How to setup Hermes with Ollama is half the battle, and picking the right model for each task is the other half. There are dozens of models on Ollama and most blog posts pretend they all work the same, but they really don't, and matching the model to the task is what separates a useful Hermes setup from a frustrating one.
This post tells you which Ollama model to pair with Hermes for each kind of task, based on what I actually run daily across SEO, content, coding, and multi-agent workflows.
How To Setup Hermes With Ollama — The Quick Answer
If you only read this far, here's the cheat sheet. Gemma 4 is the best all-rounder. DeepSeek is the best for agent workflows. Nemotron 3 Nano Omni is the best for sub-agents. Qwen 3.6 is the best for code. Gemma 4 at 7GB is the lightest pick for low-spec laptops.
Install Gemma 4 if you're new and switch to DeepSeek when you're doing serious agent work.
How To Setup Hermes With Ollama In 5 Minutes
Quick setup before we get into the model picks.
1 — Install Ollama
Visit ollama.com, download the installer, and run it. Ollama runs as a local server on http://localhost:11434.
2 — Install Hermes
Run the standard Hermes install from the GitHub repo. If terminals scare you, use Claude Code or Codex to run the install — paste the command and ask "set this up" and it'll handle the rest.
3 — Pull a model in Ollama
Run a terminal command like ollama run gemma4 or ollama run deepseek to pull and load the model.
4 — Connect Hermes to Ollama
In your Hermes config, set the provider to ollama, the URL to http://localhost:11434, and the model to your downloaded model name.
5 — Send a test message
If you get a reply, you're set up. Now let's talk about which model to pick.
Gemma 4 — The Beginner's Default
Gemma 4 is small at 7GB, fast on most hardware, and surprisingly capable for its size.
I recommend Gemma 4 if you're on a laptop with 8 to 16GB of RAM, you want a working setup in 5 minutes, or you're testing Hermes for the first time. It handles short writing tasks, summarisation, and basic reasoning fine, which covers a huge chunk of daily use cases.
I covered Gemma 4 specifically in Hermes Gemma 4 for the full walkthrough.
DeepSeek — The Agent Workhorse
DeepSeek is built specifically for agent tasks and it shows. Tool use is solid, multi-step reasoning works well, and it's sized to fit on most modern machines without melting them.
Use DeepSeek when you're running Hermes with skills like web search, browser, or terminal, when you want better reasoning than Gemma 4 can deliver, or when you're doing real agentic work rather than just chat. I cover DeepSeek deeper in Hermes DeepSeek.
Nemotron 3 Nano Omni — The Sub-Agent King
Nvidia's recent release at 28GB is designed specifically for agentic tasks at scale. The best feature is that it's tuned to power sub-agents in multi-agent setups.
Use Nemotron 3 when you're running multi-agent setups, when you want each sub-agent to be efficient and focused, and when you've got the RAM (32GB+ recommended). If you're playing with Hermes agent workspaces where you have a brain agent plus sub-agents, this is the sub-agent model.
Qwen 3.6 — Best For Code
Qwen 3.6 has stronger code generation than Gemma or DeepSeek, full stop.
Use Qwen 3.6 when your Hermes agent does coding tasks, when you're integrating with file or terminal skills, and when you want cleaner code output. The cloud equivalent if you go free cloud is Qwen 3.5 Cloud.
🔥 Want my full Hermes model stack? Inside the AI Profit Boardroom, I share my model picks per use case, system prompts per agent, and a 2-hour Hermes course covering every config. Plus weekly live coaching where you can share your screen and we'll dial your Ollama setup. 3,000+ members. → Get the stack here
Models To Avoid Or Use Carefully
Three categories to be cautious with.
1. Anything 70B+ on a normal laptop will crash or be unusably slow. Don't fight your hardware.
2. Older models pre-2024 mostly aren't agent-tuned and will struggle with tool use even when they work for chat.
3. Vague general-purpose models without agent benchmarks are a gamble. Stick to the picks above unless you're testing for fun.
Free Cloud Models Inside Hermes
If your hardware can't handle local, Hermes also supports free cloud tiers. The recommended free cloud picks are Kimi K2.5 for strong reasoning, GLM 5.1 for a solid all-rounder, Qwen 3.5 Cloud for code-friendly work, and Minimax M2.7 Cloud for consistency.
These have token limits but they're genuinely usable for testing. I cover Kimi specifically in Kimi K2.6 Agent Swarms.
Picking By Hardware
Here's the honest breakdown by RAM tier.
For 8GB RAM laptops, run Gemma 4 and don't try anything bigger. For 16GB RAM laptops, run Gemma 4 daily and DeepSeek for serious tasks. For 32GB RAM machines, run DeepSeek as default with Nemotron 3 for sub-agents and Qwen 3.6 for code. For 64GB+ machines, run anything you want and mix and match per agent.
How To Setup Hermes With Ollama By Use Case
Match the model to the work and you'll be far happier.
For daily chat, Gemma 4. For research with the web search skill, DeepSeek. For multi-agent setups, Nemotron 3 for sub-agents plus DeepSeek for the brain agent. For code generation, Qwen 3.6. For long-form writing, Gemma 4 or DeepSeek. For background automation, whatever runs reliably on your machine without burning electricity.
Switching Models Quickly
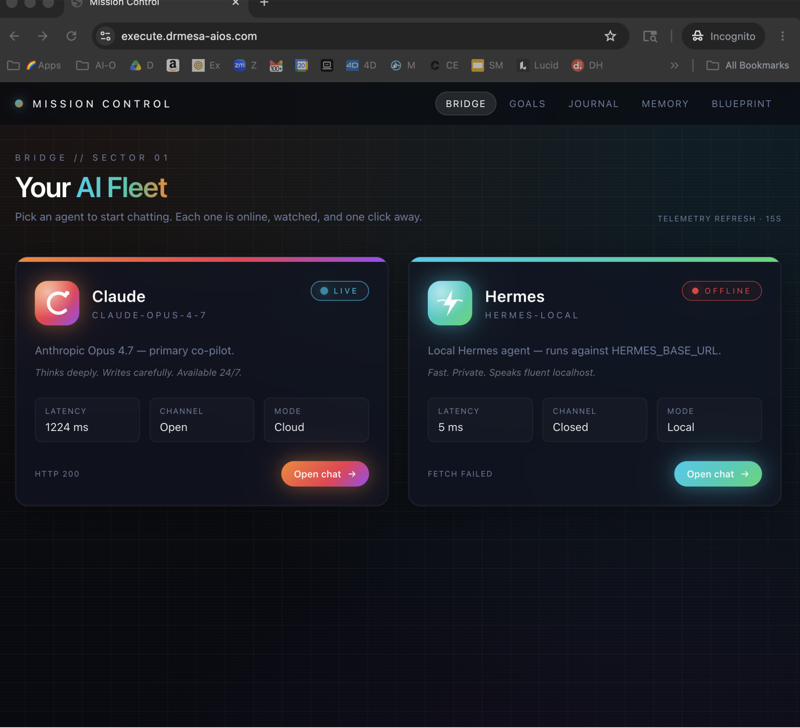
Hermes lets you swap models without reinstalling. In the Hermes config, change the model name and restart. You can also have multiple model entries in config and point different agents at different models.
This is one of Hermes' best features and matches what's possible in Hermes Agent Mission Control.
Three Common Model-Picking Mistakes
These mistakes account for most of the bad first weeks I see new users have.
1. Picking too big. People install the biggest model "just in case" and their machine crashes. Match the model to your RAM, not your ambitions.
2. Picking too small. Tiny models can't handle tool use well. Don't go below Gemma 4 size if you're doing real agent work.
3. Not matching model to task. A code-tuned model writes worse poetry. Pick by use case, not vibes.
The Real Cost Of Free Local
Be straight about the costs. Free Ollama models cost disk space (each model is 5 to 28GB), a few pence a day in electricity, and some upfront time to learn what works for you.
That's still 95% cheaper than running cloud APIs daily, so the trade is heavily in your favour.
🚀 Want a full Hermes + Ollama playbook? The AI Profit Boardroom has the 2-hour Hermes course, my model rotation rules, and weekly live coaching. Plus daily training drops on AI agents and SEO. 3,000+ members. → Join here
FAQ — Best Hermes Ollama Models
Which Ollama model is best for Hermes overall?
DeepSeek for serious agent work. Gemma 4 for lightweight machines.
Can I run multiple Ollama models in Hermes?
Yes. Define them as separate providers in config and switch as needed.
What's the smallest model that works well?
Gemma 4 at around 7GB is the floor. Smaller models struggle with tool use.
Do I need a GPU?
Not strictly. Ollama uses CPU and GPU as available, and a modern laptop CPU handles small models fine.
Which model is best for web scraping?
DeepSeek wins thanks to solid tool use and reasoning.
Which model is best for code generation?
Qwen 3.6 or its cloud variant Qwen 3.5.
Should beginners use cloud or local?
Local with Gemma 4 is the easiest start at zero cost.
Related Reading
- Hermes Gemma 4 — full Gemma 4 walkthrough.
- Hermes DeepSeek — best agentic model setup.
- Hermes Agent Mission Control — managing multiple Hermes agents.
📺 Video notes + links to the tools 👉
🎥 Learn how I make these videos 👉
🆓 Get a FREE AI Course + Community + 1,000 AI Agents 👉
That's how to setup Hermes with Ollama and pick the right model for the job — no more guessing which one to install.